|
I am a senior software engineer at Google Research, Perception. My research interest lies at the intersection of computer vision and machine learning, with the focus on optical character recognition (OCR). Previously, I received my B.E. degree from Tsinghua University and Ph.D. degree from University of California, Santa Cruz, advised by Professor Roberto Manduchi.qinb[at]google.com / Google Scholar / LinkedIn / GitHub |

|
|
|
|
|

|
Shangbang Long, Siyang Qin, Dmitry Panteleev, Alessandro Bissacco, Yasuhisa Fujii, Michalis Raptis CVPR 2022 arXiv / github |
|
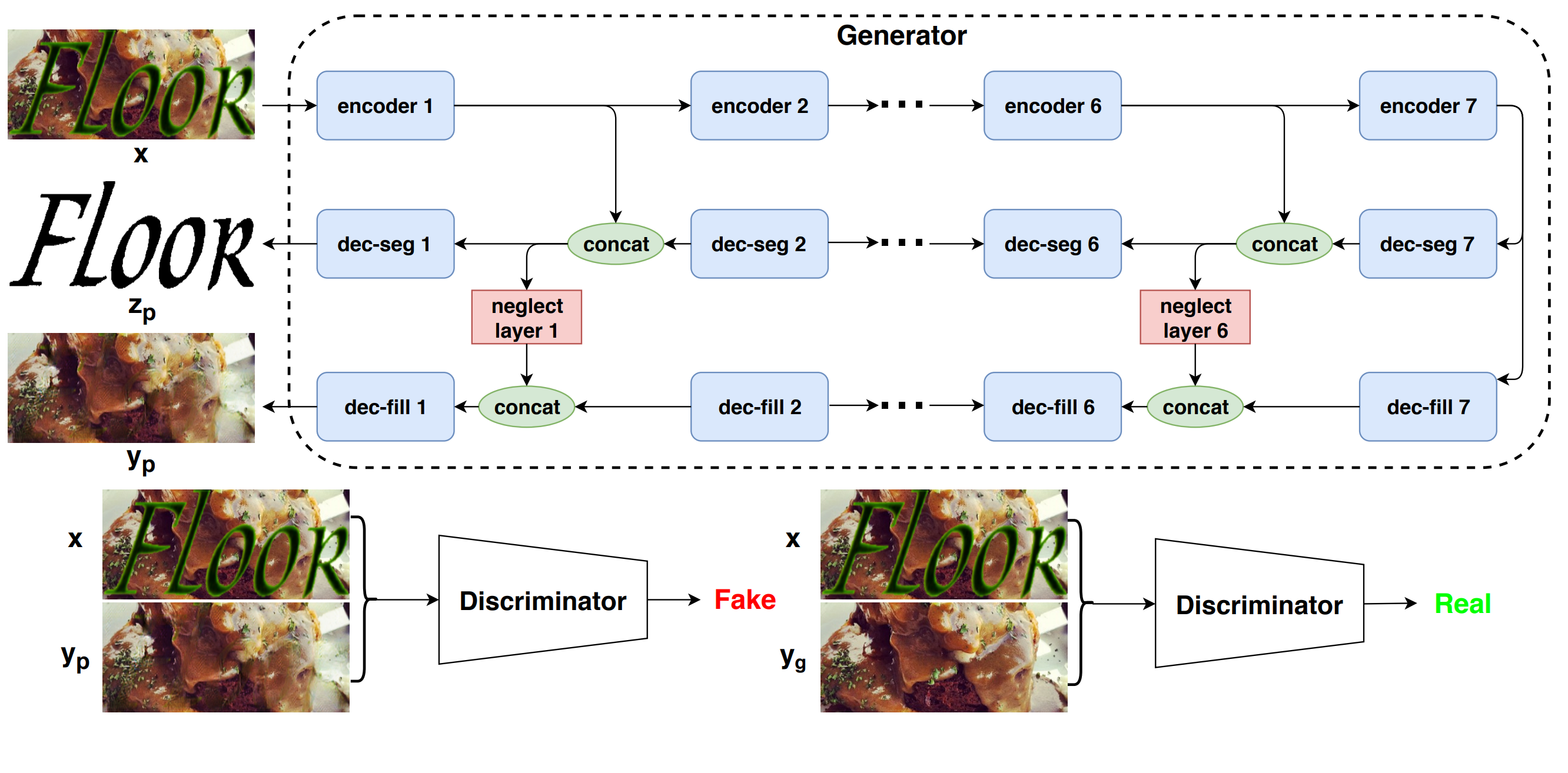
Chen-Yu Lee, Chun-Liang Li, Chu Wang, Renshen Wang, Yasuhisa Fujii, Siyang Qin, Ashok Popat, Tomas Pfister ACL 2021 (Oral Presentation) arXiv |

|
Daniel Hernandez Diaz, Siyang Qin, Reeve Ingle, Yasuhisa Fujii, Alessandro Bissacco arXiv |

|
Siyang Qin, Alessandro Bissacco, Michalis Raptis, Yasuhisa Fujii, Ying Xiao ICCV 2019 (Oral Presentation) paper |

|
Leo Neat, Ren Peng, Siyang Qin, Roberto Manduchi IUI 2019 paper |
|
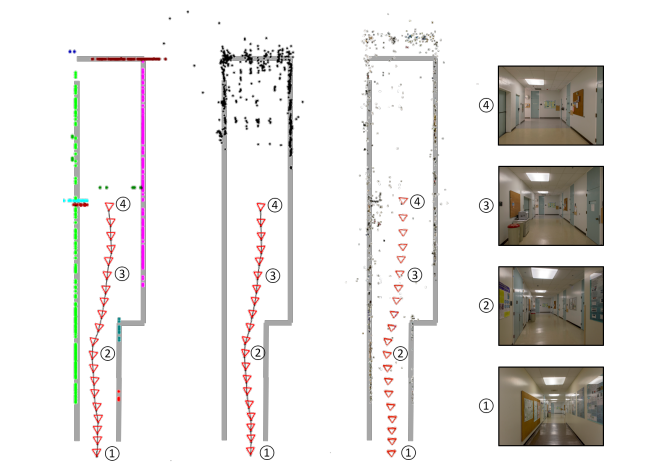
Siyang Qin, Jiahui Wei, Roberto Manduchi BMVC 2018 (Best Industry Paper Award) arXiv |
|
Seongdo Kim, Roberto Manduchi, Siyang Qin 3DV 2018 paper |

|
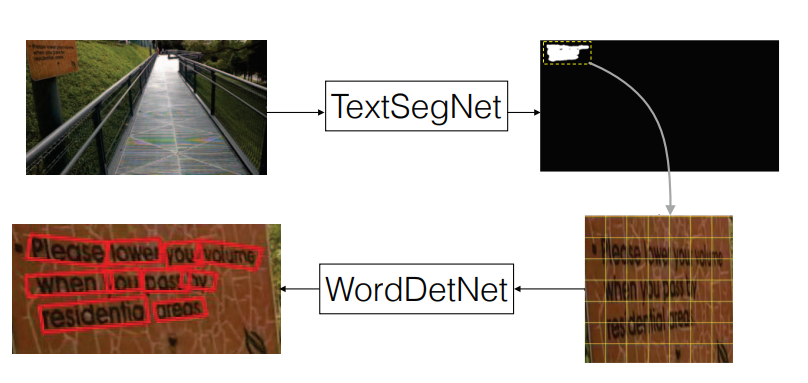
Siyang Qin, Peng Ren, Seongdo Kim, Roberto Manduchi WACV 2018 paper |
|
Siyang Qin, Roberto Manduchi ICDAR 2017 paper |

|
Siyang Qin, Seongdo Kim, Roberto Manduchi ICME 2017 (Oral Presentation) paper |

|
Siyang Qin, Roberto Manduchi WACV 2016 paper |

|
Jing Liu, Tom Malzbender, Siyang Qin, Bipeng Zhang, Che-AnWu, James Davis IS&T/SPIE Electronic Imaging, 2015 paper |
|
Source code credit to Dr. Jon Barron |